import BigKindsParser as bkp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import gensim
import warnings
warnings.filterwarnings("ignore")
plt.rcParams["font.family"] = "Malgun Gothic"
plt.rcParams["figure.figsize"] = 10,10
plt.rcParams["axes.unicode_minus"] = False
df = pd.read_excel('./data/econo_columns_20170510-20220509.xlsx', engine = "openpyxl")3 Topic Modeling을 중심으로
3.1 개요
본 내용은 1편에 이어 단어 군집 분석 방법인 토픽 모델링으로 분석을 진행한 보고서이다.
분석 언어는 Python을 사용했으며, 가장 보편적인 토픽모델링 방법인 LDA(Latent Dirichlet Allocation)를 사용했다.
알고리즘은 gensim 라이브러리의 LDA 모델을 사용했으며, 중간에 하이퍼파라미터 튜닝의 작업을 거쳤다.
3.2 최적 토픽 갯수 추론
먼저 해당 기사의 최적 토픽 갯수를 추론하기 위해 전처리의 과정을 거쳤다.
keywords = bkp.keywords_list(df)
news_words = bkp.keyword_parser(keywords)
news_dict = gensim.corpora.Dictionary(news_words)
corpus = [news_dict.doc2bow(text) for text in news_words]3.2.1 Perplexity
가장 먼저 Perplexity를 통해 최적 토픽 갯수 추론을 시도하였다. Perplexity란, 선정된 토픽 개수마다 학습시켜 가장 낮은 값을 보이는 구간을 찾아 최적화된 토픽의 개수 추론하는 방법론이다.
이는 확률 모델이 결과를 얼마나 정확하게 예측하는지 판단하는 척도로도 활용된다.
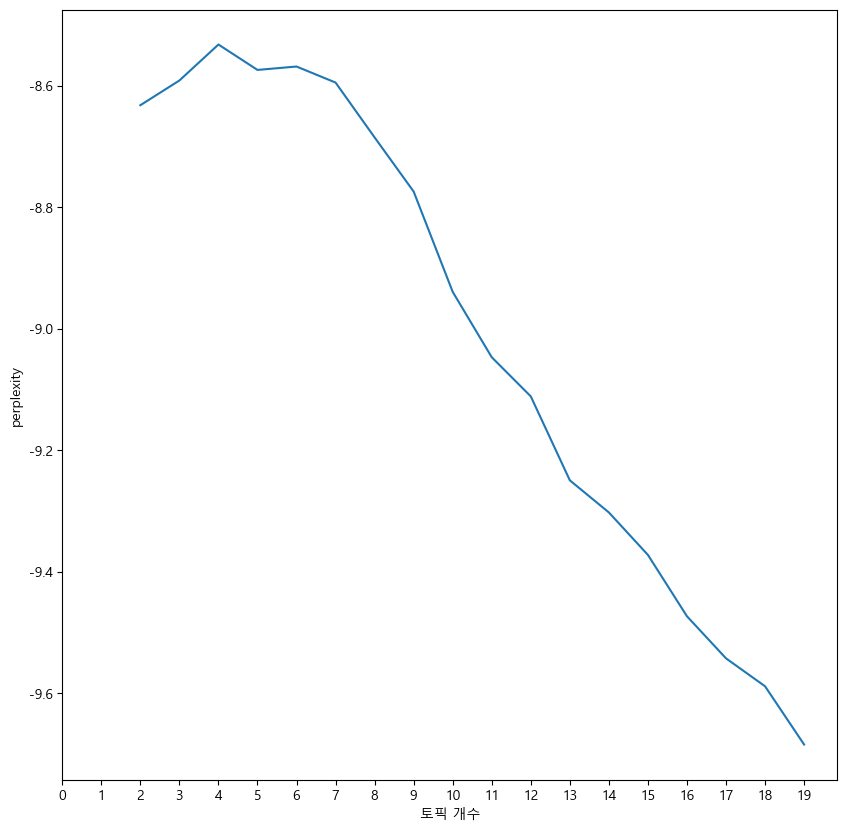
그러나 결과적으로 Perplexity는 음수를 나타내고 있어, 해당 문서의 최적 토픽 갯수 추론으로 적합한 방법이 아닌 것으로 밝혀졌다.
3.2.2 Coherence Score
그 다음으로 Coherence Score를 통해 최적 토픽 갯수 추론을 시도하였다. Coherence는 반대로 선정된 토픽 개수마다 학습시켜 가장 높은 값을 보이는 구간을 찾아 최적화된 토픽의 개수 추론하는 방법론이다.
이는 토픽이 얼마나 의미론적으로 일관성 있는지 판단하는 척도로 활용된다.
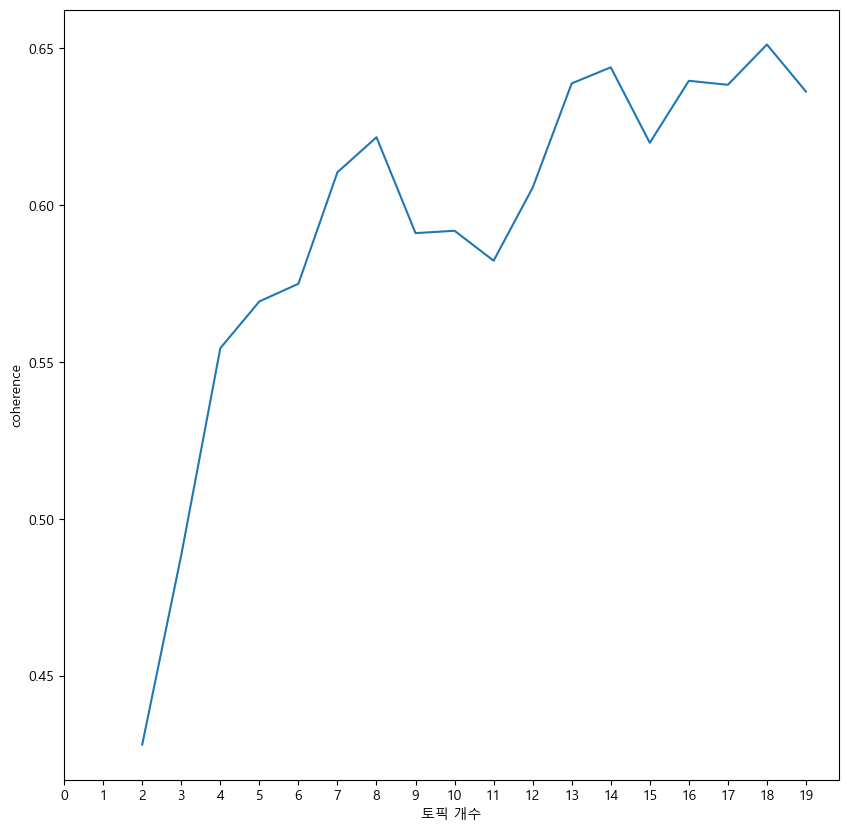
분석 결과, 18개에서 가장 높은 Coherence score가 나타났다.
3.3 토픽 모델링
Coherence score를 토대로, 모델 학습을 진행하였다. 정확도를 높이기 위해 pass는 15, 반복 횟수는 100회로 높게 잡았다.
토픽 별 상위 5개 단어는 하단과 같다.
NUM_TOPICS = 18
ldamodel = gensim.models.ldamodel.LdaModel(corpus, num_topics = NUM_TOPICS, id2word=news_dict, passes=15, iterations=100)
topics = ldamodel.print_topics(num_words=5)
for topic in topics:
print(topic)(0, '0.021*"공공" + 0.020*"국민" + 0.019*"연금" + 0.019*"정부" + 0.018*"의료"')
(1, '0.033*"금융" + 0.024*"규제" + 0.024*"은행" + 0.020*"시장" + 0.015*"서비스"')
(2, '0.033*"정부" + 0.022*"예산" + 0.020*"재정" + 0.015*"지원" + 0.011*"국가"')
(3, '0.030*"기업" + 0.014*"경영" + 0.011*"투자" + 0.010*"정부" + 0.008*"구조"')
(4, '0.049*"북한" + 0.034*"미국" + 0.023*"대통령" + 0.017*"트럼프" + 0.012*"회담"')
(5, '0.024*"국민" + 0.023*"후보" + 0.023*"선거" + 0.022*"정치" + 0.019*"대표"')
(6, '0.049*"국회" + 0.018*"여당" + 0.015*"여야" + 0.015*"법안" + 0.013*"의원"')
(7, '0.035*"일자리" + 0.032*"임금" + 0.023*"정부" + 0.022*"최저" + 0.018*"고용"')
(8, '0.036*"기업" + 0.029*"규제" + 0.021*"산업" + 0.019*"정부" + 0.018*"경제"')
(9, '0.041*"중국" + 0.023*"미국" + 0.021*"한국" + 0.014*"일본" + 0.013*"반도체"')
(10, '0.018*"사고" + 0.017*"발생" + 0.017*"안전" + 0.013*"처벌" + 0.011*"사회"')
(11, '0.042*"대통령" + 0.027*"정부" + 0.020*"청와대" + 0.019*"장관" + 0.016*"정책"')
(12, '0.033*"경제" + 0.018*"성장" + 0.012*"한국" + 0.010*"경기" + 0.010*"금리"')
(13, '0.037*"원전" + 0.026*"정부" + 0.018*"탈원전" + 0.017*"에너지" + 0.014*"정책"')
(14, '0.055*"교육" + 0.047*"대학" + 0.026*"교육부" + 0.024*"인재" + 0.017*"학교"')
(15, '0.031*"검찰" + 0.026*"수사" + 0.020*"의혹" + 0.015*"사건" + 0.009*"비리"')
(16, '0.025*"정부" + 0.024*"부동산" + 0.018*"시장" + 0.018*"주택" + 0.017*"서울"')
(17, '0.043*"노조" + 0.018*"일본" + 0.013*"노사" + 0.013*"파업" + 0.010*"요구"')해당 결과를 LDAvis를 통하여 시각화 작업을 진행하였다.
import pyLDAvis.gensim_models
pyLDAvis.enable_notebook()
vis = pyLDAvis.gensim_models.prepare(ldamodel, corpus, news_dict)
pyLDAvis.display(vis)